


.jpg)
Platform
What is Data Lineage: A Practical Implementation Guide

.jpg)
If data is the new oil, then a robust, scalable data pipeline is the refinery. For industrial OEMs and enterprises, the difference between merely collecting data and extracting measurable business value, it all comes down to architectural design. And as they say, in 2025 staying ahead of the curve means mastering cutting-edge patterns that turn machine, sensor, supply chain, and asset data into competitive advantage. Without this, all your data would be considered a big pile of non-usable numbers.
Industrial OEMs and enterprises are awakening to the reality that their manufacturing lines, connected devices, and supply chain platforms generate an unprecedented torrent of data—often exceeding terabytes per day or even more. But wrangling this data into real-time dashboards, predictive maintenance models, and digital twin applications requires far more than bolting on what’s trending or implementing a cool technology. It’s about architecting data pipelines that are reliable, modular, and fail-proof.
Recent surveys show that more than 60% of large manufacturers and enterprises have experienced costly downtime or delays due to brittle, siloed legacy data flows. Conversely, the leaders—those already embracing modern, cloud-native patterns—are reporting 30-50% gains in operational visibility and a marked uptick in smart automation. With time, everybody has understood the chaos in the data means chaos in the business itself.
At its most basic, a data pipeline is an engineered series of steps that move data from source (say, a CNC machine’s sensor array or ERP platform) to destination (like a cloud data warehouse, machine learning model, or executive dashboard), transforming and validating as it goes.
In industrial environments, complexity multiplies: the pipeline might ingest time-series sensor events, batch production reports, SAP logs, and vendor files—all in disparate formats, all under stringent uptime, compliance, and latency requirements.
Unlike pure-play web companies, industrial OEMs deal with on-premises OT (Operational Technology), strict SLAs, “noisy” machine data, and regulatory hoops. The stakes are high: errors aren’t just annoying—they can disrupt a critical supply chain or jeopardize product quality, which leads to larger mishappenings when not catered on time.
1. Batch Processing: Still Essential, But Not Enough

Batch pipelines are designed for high-volume data workloads wherein the data is batched together in a specific time frame (i.e hourly, weekly, monthly, etc). The data formats on which batch processing works might consist of files in different formats (JSON, CSV, Parquet, etc) and can be stored in different cloud object stores or even data stores.
Batch-oriented ETL (extract-transform-load) remains a staple for aggregating daily production logs or monthly inventory snapshots. But on its own, batch can’t power use cases like real-time quality assurance or instant equipment failure response.
2. Streaming and Event-Driven Processing: The Industrial Edge
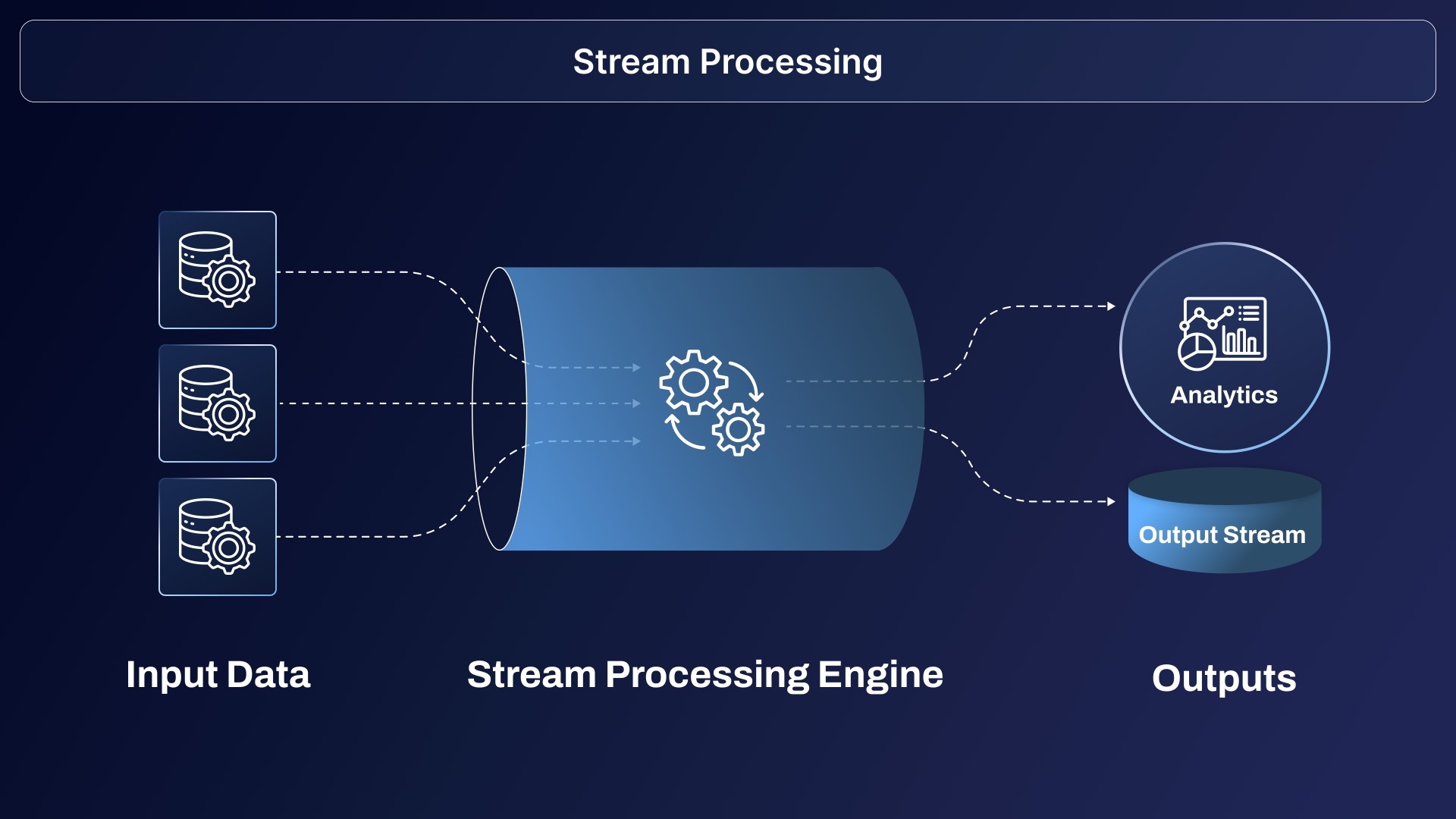
Streaming data pipelines have become the backbone of modern factory floors and Industrial IoT deployments. Using platforms like Apache Kafka and MQTT, manufacturers feed machine telemetry, EPC (equipment performance data), and environmental signals directly to analytics engines—enabling anomaly detection, predictive maintenance, and closed-loop process adjustments on the fly.
For example, a large refrigeration manufacturer shifted from manual spreadsheets and paper logs to an IoT-driven streaming architecture. Today, data is instantly pulled from machinery and MES systems, ingested by Kafka, processed via business rules in real time, and pushed into Power BI for operations teams. The results? Real-time visibility, rapid incident response, and a significant reduction in both manual errors and downtime.
3. Lambda

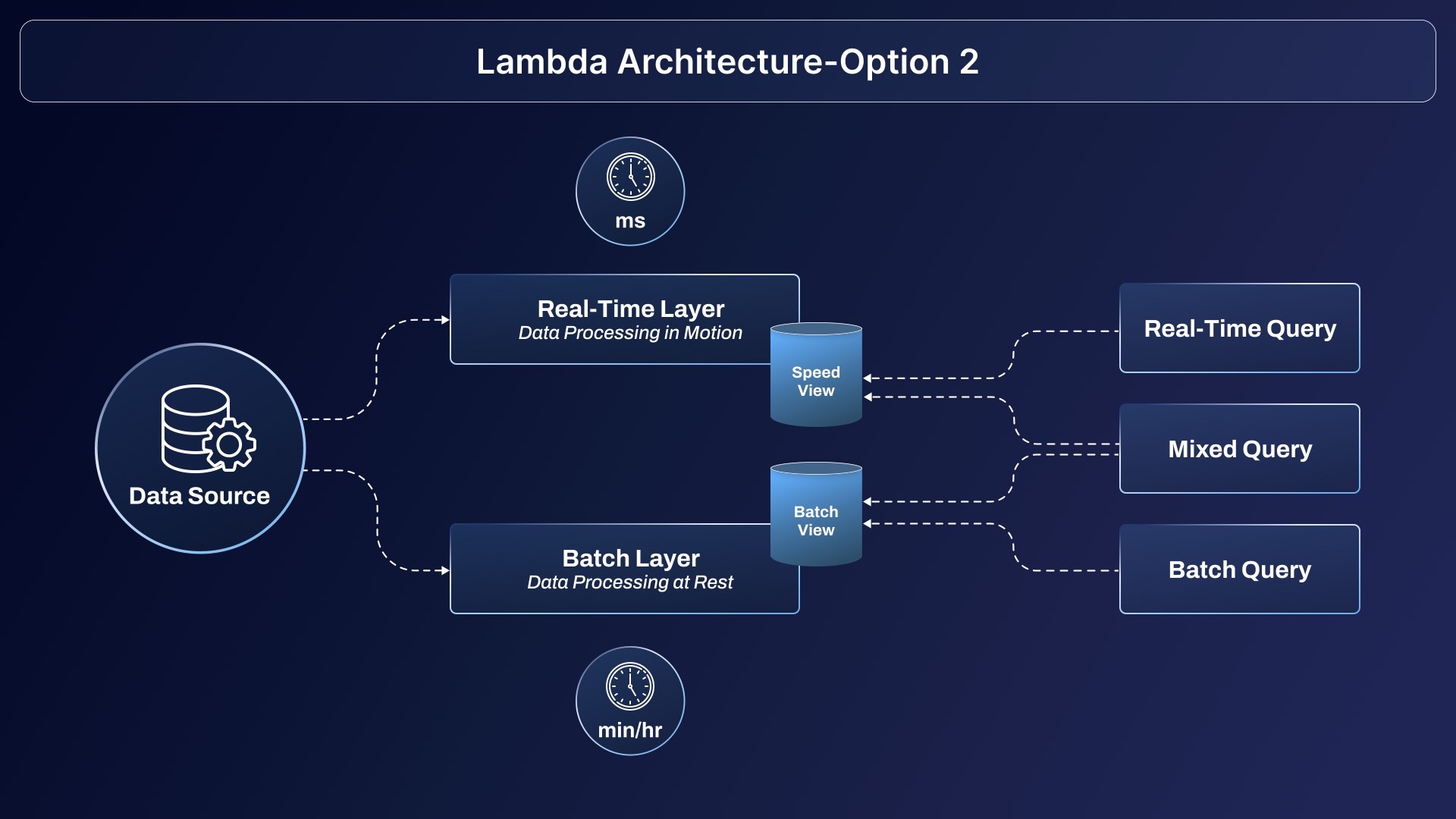
Lamba architecture is processed when both batch and stream data is needed. The Lambda architecture blends speed and reliability by layering real-time streams (for instant metrics) atop a batch processing layer (for comprehensive, historical analysis).
4. Kappa
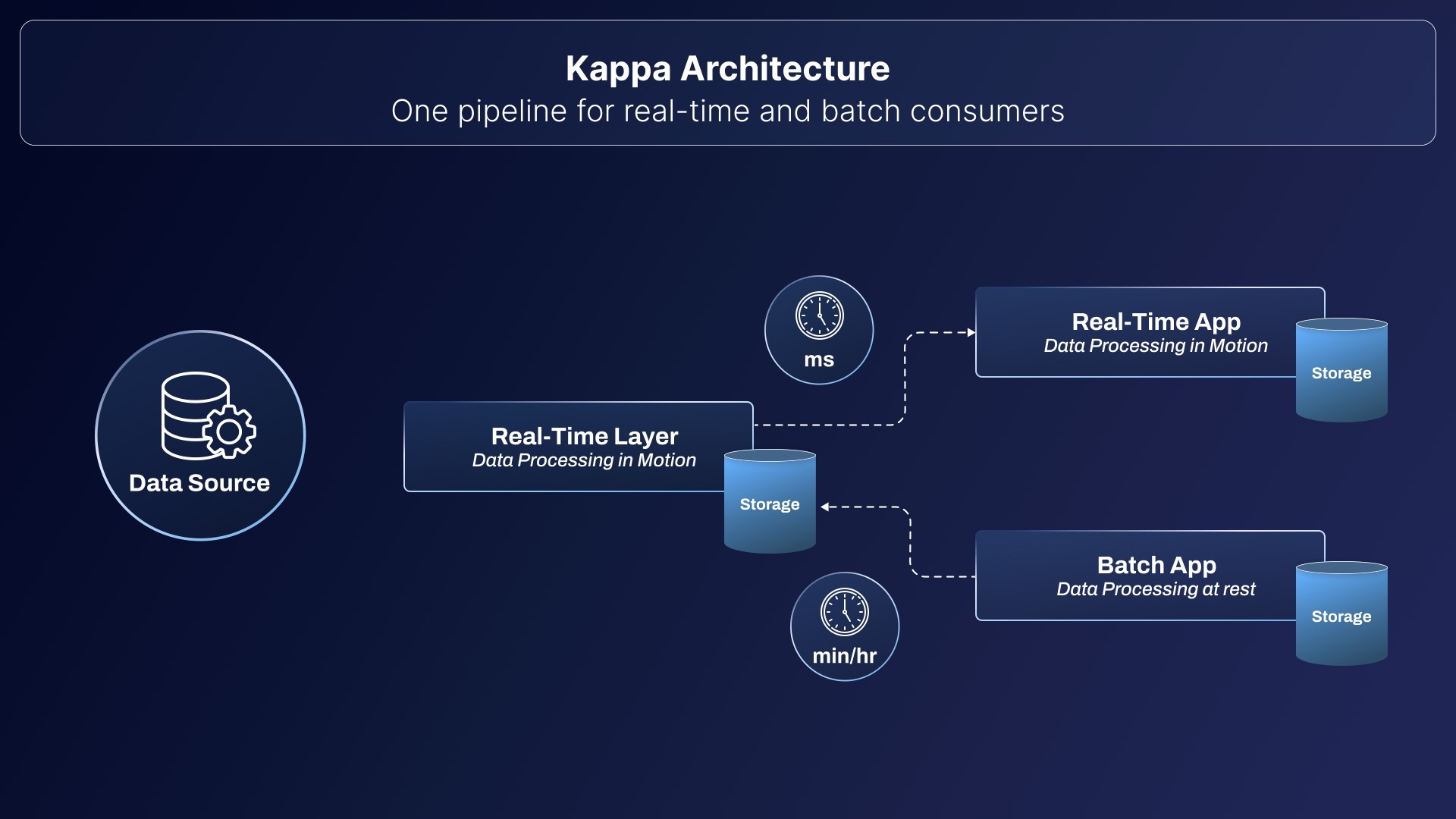
Kappa architecture is a simpler alternative to Lambda architecture. In this architecture, the batch layer is eliminated entirely, and all the processing is handled both real time and historical through a single streaming pipeline. Kappa is ideal for event-driven systems and is necessary when the data processing can be handled in real-time and does not require a separate batch system.
5. Data lake
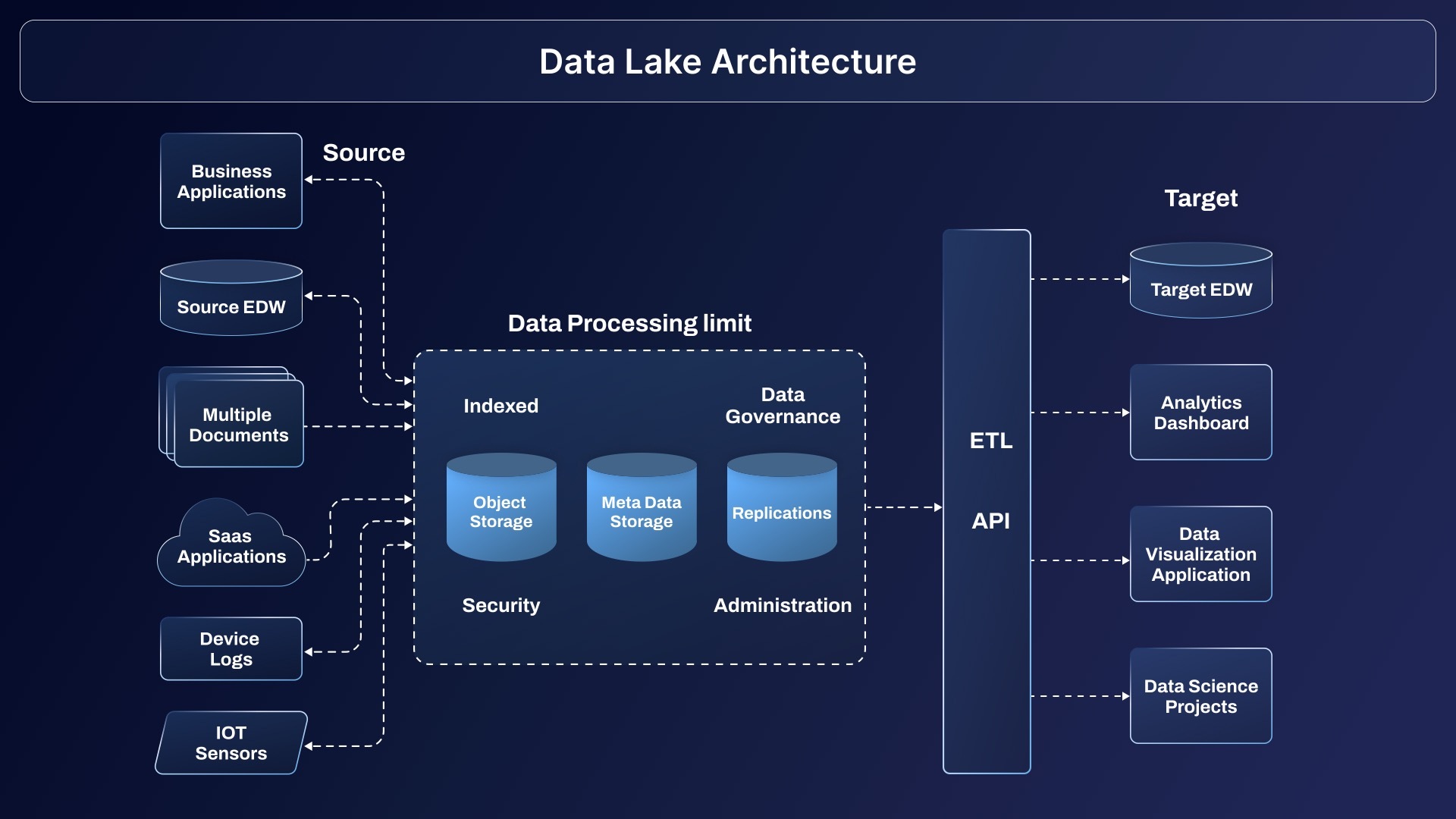
Data lakes have become synonymous with flexibility in managing both structured and unstructured data in industrial settings. Unlike traditional warehouses, the data lake stores every byte in its raw format, whether it’s sensor streams, maintenance PDFs, or batch order logs. This ensures businesses can perform advanced analytics, machine learning, and AI-driven applications on rich datasets drawn from shop floors or remote assets.
6. ETL
ETL (Extract, Transform, Load) remains a foundational pattern, particularly for OEMs integrating legacy plants or on-premises ERP data. Traditionally, ETL extracts operational records, transforms them for consistency and formatting, and loads to a warehouse or analytics-ready repository overnight. Despite its reliability, ETL can fall short in environments where real-time operations or instant responsiveness are needed.
7. ELT
ELT (Extract, Load, Transform), on the other hand, reverses the paradigm. Data is first loaded in its raw form—often directly into a data lake or modern warehouse—and then transformed using scalable compute resources, such as Spark clusters or serverless cloud platforms. This approach is perfectly suited for industrial companies performing heavy analytics, AI modelling, and multi-source integrations, as it leverages powerful engines to process large, complex datasets on demand.
Something that can’t be compromised in businesses is reliability. Pipelines must be built to handle unexpected volume spikes, network interruptions, and evolving regulatory requirements. Modularity ensures that system upgrades or new integrations don’t break the entire pipeline. Industrial-grade pipelines use:
Security and compliance are frontline concerns. Encryption in transit and at rest, fine-grained access controls, and strong governance policies are non-negotiable given increasingly strict privacy regulations and industrial espionage risks.
A modern OEM data pipeline isn’t “set and forget.” It must adapt to changing business models (servitization, Industrial IoT), new data sources (PLC upgrades, SaaS integrations), and shifting regulatory requirements.
Know how to streamline your data Pipeline.
Read the blog "Streamline Your Data Pipeline"
Consider a global industrial OEM operating hundreds of manufacturing lines worldwide. The legacy approach—relying on human inspections and off-line reporting—led to unexpected breakdowns and excess spare parts inventory.
The new architecture was built around three primary layers:
The impact was dramatic: mean time between failures increased by 35%, unplanned downtime dropped by nearly half, and maintenance costs fell by over 30%.
By shifting to a streaming-first, modular pipeline, the OEM now supports factory expansions and AI model rollouts without major re-architecture.
The pace of change in industrial data engineering shows no signs of slowing. 2025 brings new surge in surge in trends like:
According to recent studies, around 70% of industrial enterprises plan to double down on real-time, cloud-native, and federated data pipeline investments in the next two years—a sign that data pipeline maturity is now foundational to digital transformation, not just IT modernization.
For industrial OEMs and enterprises, a modern data pipeline isn’t just a technical asset—it’s a strategic enabler. The most successful organizations are those that invest in resilient, adaptive architectures, champion best practices, and never lose sight of the real-world operational impact. As enterprise data, AI, and IoT become ever more entwined, the right data pipeline architecture is the hidden engine that powers tomorrow’s efficiency, innovation, and growth.
If your organization is ready to evolve beyond legacy batch jobs and fragmented integrations, now is the time to rethink and retool—because in industrial transformation, the future belongs to those who move data (and act on it) faster than the competition.

%20(1).jpg)



.jpg)