Process Data as Business Needs—Not How a Platform Dictates
Real-time data analytics, batch processing, and complex event processing unified on a single AIoT platform. From edge to cloud, Flex83 orchestrates your entire data journey through end-to-end data pipeline management.

Why Unified Data Processing Matters
Industrial operations generate unprecedented data volumes from connected assets, legacy systems, and cloud-native sources. Traditional architectures force teams to maintain separate platforms for real-time data streaming analytics, batch processing, and event management—fragmenting insights, multiplying costs, and slowing decision-making.
No more stitching together Kafka, Spark, and separate analytics databases. Flex83 orchestrates all three natively, with an integrated architecture.
Configure data pipeline automation workflows that match operational reality—not platform limitations.
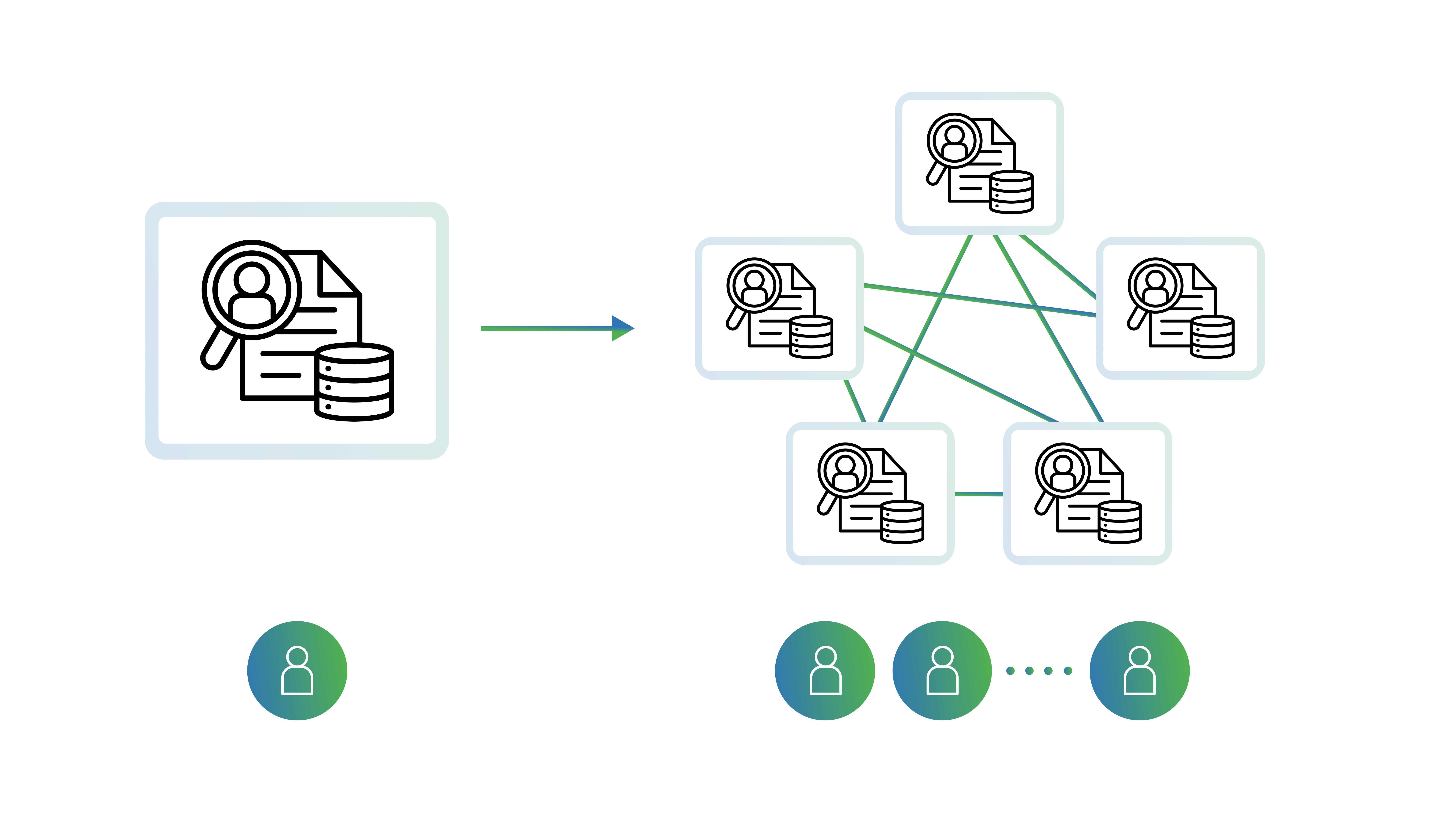
From POC to millions of assets, with 6x lower TCO and maintained data governance.
Stream Processing & Analytics
With support for OPC UA, MQTT, Sparkplug, WebSocket, Apache Kafka and more, Flex83 turns device data ingestion into intelligent workflows via edge ML capabilities.
.png)
Data Ingestion
OPC UA, MQTT, Modbus/TCP, REST, WebSocket, Kafka
Heterogeneous device ecosystems with automatic schema alignment
.avif)
Transformation & Enrichment
Low-latency field data transformation
AI ML-driven feature engineering at ingestion time
.png)
Analytics & Aggregation
Sub-second data streaming windows and time-series aggregations
Correlation analysis across connected assets streams
.avif)
Event Detection & Alerting
Pattern recognition and anomaly scoring on live data
Custom rule evaluation engines
Multi-level notification routing
.png)
Edge Intelligence & Local Processing
Embedded Edge Agent for on-device filtering and inference
Local alerts and offline buffering with secure cloud sync
Optimized for low network bandwidth and latency-sensitive ops
.avif)
Streaming Storage & Access
Time-series optimized databases for high-throughput ingestion
Immediate query-ability for data streaming without delay
Automatic retention policies and archival workflows
Batch Processing & Historical Analysis
While real time data streaming captures immediate events, enterprise-scale decisions require analysis of months or years of historical data. Batch processing over complete datasets brings trends invisible in isolated time windows such as seasonal patterns, equipment degradation arcs, and process inefficiencies spanning multi-month cycles.
Petabyte-Scale Data Lake Storage
Multi-format support: Parquet, Delta Lake, Apache Iceberg
Time-series data optimized for historical queries
Automatic data lifecycle management and compression
Distributed Batch Query Engine
Apache Spark SQL for complex OLAP queries
Support for custom DAG workflows and multi-step transformations
Parallel data processing across commodity clusters
Advanced Analytics & ML Feature Generation
Historical cohort analysis (compare performance across time periods)
Derived feature computation from raw telemetry (moving averages, rolling correlations, spectral features)
Integration with ML frameworks (scikit-learn, TensorFlow, XGBoost)
Data Quality & Validation at Scale
Automated anomaly detection in historical datasets
Schema validation and reconciliation across data ingestion windows
Data lineage and audit trails for compliance
Self-Service Data Discovery
AI-Genie natural language query interface
Metadata catalog for operators, analysts, and business teams
Role-based access control to sensitive historical data
Export & Integration
APIs for downstream data analytics platforms and BI tools
Scheduled batch export to enterprise data warehouses
Support for third-party visualization (Tableau, Power BI, Grafana)
Complex Event Processing
Enable systems to recognize sophisticated multi-step patterns: a temperature rise followed by pressure increase while vibration exceeds baseline and humidity drops below setpoint. A CEP translates these orchestrated conditions into immediate, contextual actions without human intervention.
.png)
Integrate data across systems, assets, and protocols.
Manage real-time streams through one unified layer.
Support both generic and FlexIoT-native data streams.
Correlate events across dozens of simultaneous data sources
Cross-asset pattern matching (failure in Asset A triggered by condition in Asset B)
Time-window based event deduplication and prioritization
Run scheduled jobs across lakehouse data pipelines.
Move and transform data between FlexLake and FlexCube.
Support scalable historical processing and downstream delivery.
Trusted by global enterprises you already aware of

Head of Product, Actiontec
The FLEX83 as an Application Enablement Platform (AEP) was easily customized to handle our sophisticated and high-scale application. The IoT83 team worked with us to deliver this high-quality solution in a very short time.

Networks
IoT83 is revolutionizing the industrial IoT by enabling digital transformation with its secure & scalable platform (Flex83), its application tools, and agile services, streamlining the big data deployments in a cost-effective manner for a faster and increased ROI.

Product Lead
The software is very easy to use & intuitive. FLEX83 has been extremely helpful & committed to nVent success moving the company forward with connecting our legacy installed controller base to the cloud platform.

Electronics
IoT83's cloud platform (Flex83) enabled Vision AI applications on Renesas Virtual Lab's RZ/V series MPUs. It supports RZ/V2M and RZ/V2L evaluation boards, using standard ONNX models and a DRP-AI translator. This solution performs AI inference while delivering metrics like FPS, FPS/Watt, and Inference Time.

American Appliance, OEM
When working with Flex83, you are not just getting a world-class Application Enablement Platform (AEP), you are also gaining access to some of the brightest Dev Minds in the cloud space. It added immense value to our operations.
Global Industrial Manufacturer
We operate across more than a million connected assets, and our problem was never too little data; it was data scattered across too many systems. What worked for us wasn't a rip-and-replace platform, but one that sat on top of what we already ran and pulled everything into a single real-time view. Along with that, we kept full ownership of our data and IP, went from idea to deployment far faster than expected, and at a fraction of the hyperscaler cost.
Head of Product, Actiontec
The FLEX83 as an Application Enablement Platform (AEP) was easily customized to handle our sophisticated and high-scale application. The IoT83 team worked with us to deliver this high-quality solution in a very short time.
Networks
IoT83 is revolutionizing the industrial IoT by enabling digital transformation with its secure & scalable platform (Flex83), its application tools, and agile services, streamlining the big data deployments in a cost-effective manner for a faster and increased ROI.
Product Lead
The software is very easy to use & intuitive. FLEX83 has been extremely helpful & committed to nVent success moving the company forward with connecting our legacy installed controller base to the cloud platform.
Electronics
IoT83's cloud platform (Flex83) enabled Vision AI applications on Renesas Virtual Lab's RZ/V series MPUs. It supports RZ/V2M and RZ/V2L evaluation boards, using standard ONNX models and a DRP-AI translator. This solution performs AI inference while delivering metrics like FPS, FPS/Watt, and Inference Time.
American Appliance, OEM
When working with Flex83, you are not just getting a world-class Application Enablement Platform (AEP), you are also gaining access to some of the brightest Dev Minds in the cloud space. It added immense value to our operations.
Global Industrial Manufacturer
We operate across more than a million connected assets, and our problem was never too little data; it was data scattered across too many systems. What worked for us wasn't a rip-and-replace platform, but one that sat on top of what we already ran and pulled everything into a single real-time view. Along with that, we kept full ownership of our data and IP, went from idea to deployment far faster than expected, and at a fraction of the hyperscaler cost.

Niclas Anderson
VP Sales, Vitronic
Frequently Asked Questions
Do we need to replace our existing data warehouse?
No. Flex83 works alongside existing systems. Many customers use Flex83 for real time data streaming operations while maintaining their data storage warehouse for enterprise data analytics. Over time, many consolidate.
What's the learning curve for operations teams?
Minimal. Real time data streaming data processing and rule authoring are designed for ops expertise, not data engineer backgrounds. Most teams are productive within 2-3 days.
How does Flex83 handle data privacy and compliance?
Role-based access control, encryption at rest & in transit, audit logging, automated anonymization of sensitive telemetry through data pipeline security. SOC 2 Type II certified.
Can Flex83 process legacy OT protocols?
Yes. 50+ built-in connectors for industrial protocols (OPC UA, Modbus, Sparkplug MQTT) plus custom gateway support for proprietary systems through IoT connectivity options.
What happens if the cloud connection drops?
Edge ML Agent continues operating locally, buffers data securely, and syncs when connection restores. Zero data loss guaranteed.
How does pricing scale with data volume?
Simple model: pay for data ingestion ($/GB), compute ($/vCPU-hour), and data storage ($/GB-month). No per-user license. Volume discounts available.
Can I run this on-premises or private cloud?
Yes. Appliance, cloud native Kubernetes-managed, or self-hosted deployments available. Same feature set, your infrastructure for cloud agnostic deployment.
How quickly can we deploy a POC?
2-4 weeks typical. Flex83 provides architecture, sample connectors, and pre-built templates. Your data scientists focus on models, not infrastructure.