Detect anomalies in milliseconds — across millions of devices.
Building sub-second anomaly detection across millions of devices means assembling stream ingestion, stateful windowing, an ML pipeline, and an alerting system — most teams stall on the first leg. Flex83 ships all four as one platform, production-tested at 65M-endpoint scale.
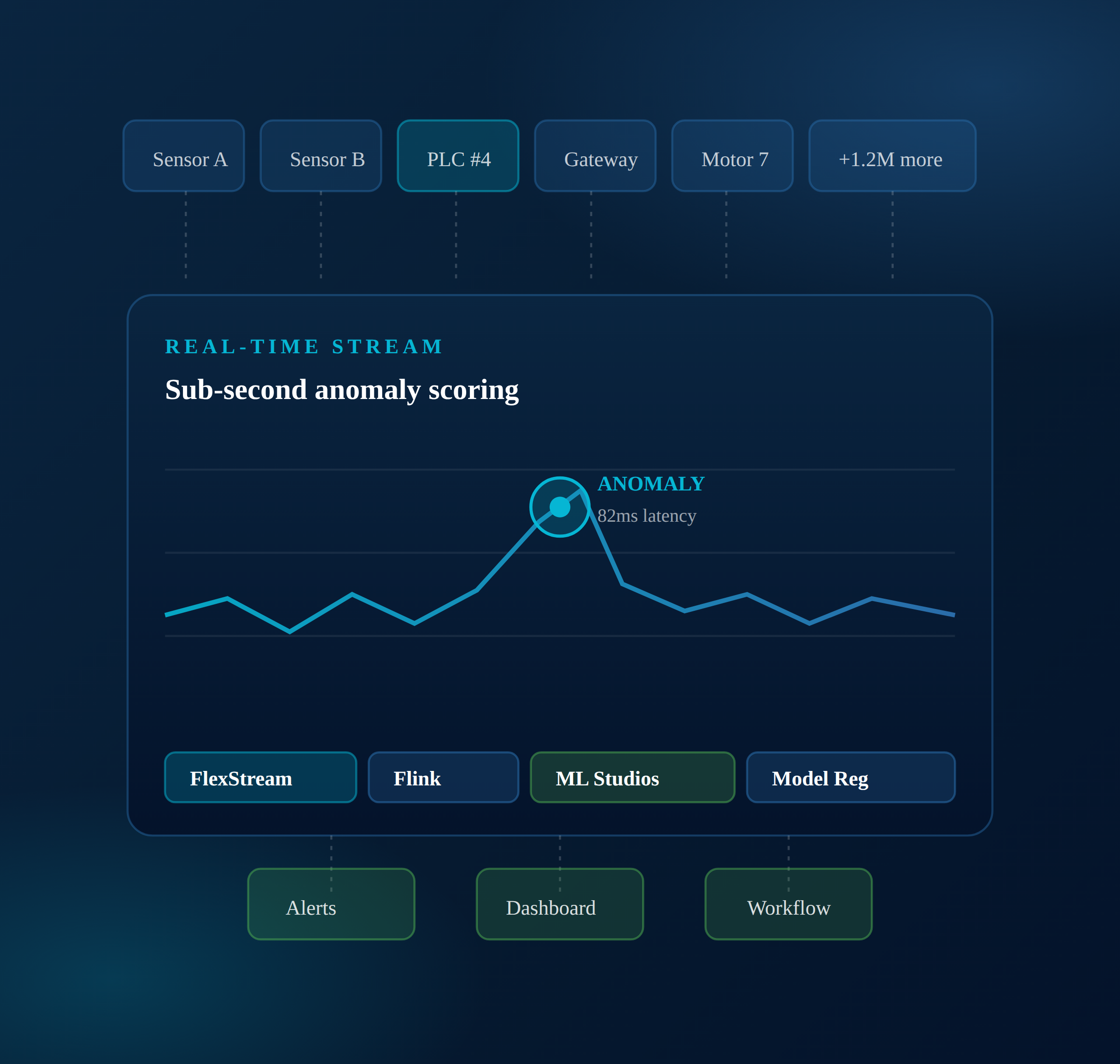
Anomaly detection at scale is where DIY pipelines break.
Detecting drift, spikes, and threshold breaches across industrial assets isn’t one engineering problem — it’s four, stitched together with tight latency budgets and no margin for error.
82%
Industrial anomaly use cases need sub-second response. Most DIY stacks built on hyperscaler primitives can’t hit that consistently.
4 systems
Ingestion + stream processor + model serving + alerting. Each fails differently. Each gets its own oncall page.
$260K
Discrete manufacturers lose $260K an hour to unplanned downtime. The point of streaming anomaly detection is to never get there.
Stream ingestion, stateful processing, and ML scoring — on one platform.
Flex83 collapses the streaming anomaly stack into one platform. FlexStream handles the ingest. Apache Flink runs the windowed enrichment. ML Studios trains and scores the models. The Model Registry versions and deploys them. Alarms and notifications close the loop.
Your data engineers build the model. Flex83 runs the pipeline.
Backpressure-aware ingest from 70+ device and OT protocols.
Stateful windowing, joins, and enrichment with sub-second latency.
Train, validate, and version anomaly models on historical telemetry.
Promote, A/B, and roll back models in production with one click.
Visual pipeline composer — no Spark or Kafka glue code.
Rule and ML-triggered alerts into email, Slack, Teams, or webhook.
From device stream to operator alert — in under a second.
A reference architecture for shipping streaming anomaly detection on top of Flex83.
FlexStream pulls telemetry from gateways, PLCs, and devices.
Flink applies stateful windows, joins, and feature engineering.
ML model scores the window in real time from Model Registry.
Threshold and ML triggers fire alarms into your downstream tools.
Operators see the anomaly in a branded dashboard and act on it.
Move from reactive monitoring to predictive operations.
Three things your engineering team stops building when Flex83 owns the pipeline.
Catch failures before they propagate
Sub-second anomaly scoring across millions of devices means alerts fire before a single machine, line, or site goes down.
Skip the streaming-team hire
No Kafka cluster, no Flink ops, no model-serving deployment. Your existing engineers ship streaming features that used to require a specialist team.
Tune models without redeploying
Model Registry lets you A/B test, roll forward, and roll back anomaly models in production. The pipeline doesn’t care which version is live.
Proven at industrial scale, today.
WiFi endpoints under real-time diagnostics on Flex83
Edge anomaly inference latency on Renesas RZ/V series
Reduction in field truck rolls from earlier anomaly detection
Devices streaming on Flex83 in production today
Stop stitching streaming pipelines. Start shipping detections.
Talk to a Flex83 platform expert about your anomaly detection roadmap. We’ll walk you through the reference architecture, the latency budget, and what it takes to go from PoC to a million devices.