Replace custom scripts with no-code DataOps for OT/IT convergence.
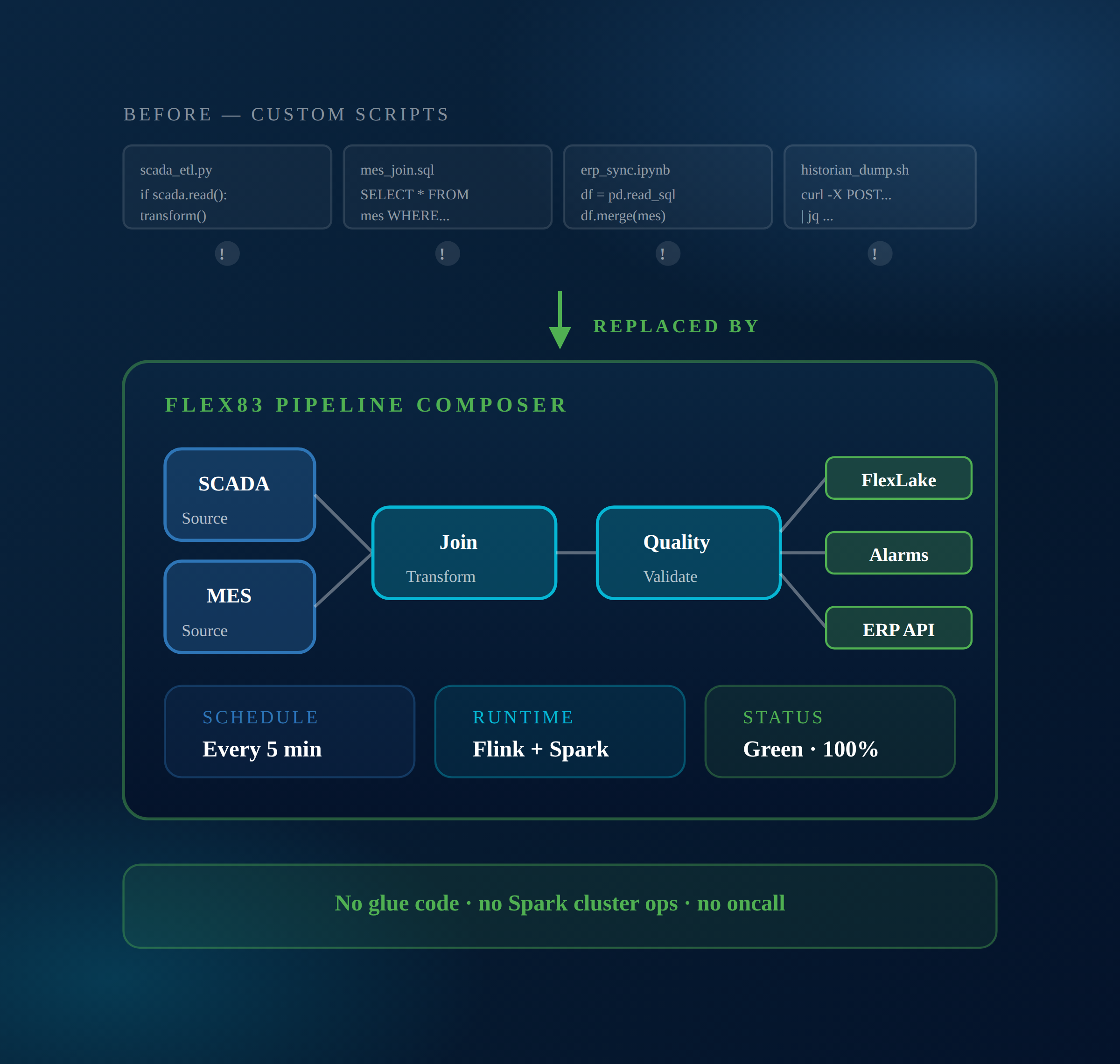
Custom Python and Spark glue between SCADA, MES, ERP, and the cloud creates technical debt no one wants to own. Every new pipeline is a maintenance burden. Flex83 ships visual pipeline composition, scheduled jobs, and managed runtime so OT and IT engineers configure flows instead of writing them.
Glue code is the slow leak in every industrial data project.
Most of an industrial data team’s output is glue code — brittle Python and SQL connecting SCADA to MES to ERP to the cloud. Every one is a maintenance burden. None of it is the product.
60%+
Industry surveys consistently report data engineers spend more than half their time on ETL plumbing, not analytics or AI. Glue code is where productivity goes to die.
Breaks
PLC firmware update changes a register. MES adds a column. ERP renames a field. Every custom script breaks — usually at 2 a.m. on a holiday weekend.
Untouched
The engineer who wrote the Spark job leaves. The Jupyter notebook with the critical join sits untouched. New work routes around old code, accumulating debt.
Configure pipelines visually. Operate them as one platform.
Flex83 ships a visual pipeline composer, a job scheduler, and managed Spark and Flink runtimes. Sources, transforms, joins, quality checks, and sinks are nodes you wire together. The platform runs them, watches them, and recovers them. Your team configures pipelines; Flex83 operates them.
Your team owns business logic. Flex83 owns the plumbing.
Visual DAG of sources, transforms, joins, and sinks — no glue code.
Cron, event-driven, and dependency-based scheduling per pipeline.
Streaming SQL for OT and IT engineers — not Java, not Scala.
Managed batch compute — no cluster sizing, no version maintenance.
Push transformed data back to MES, ERP, dashboards, or downstream tools.
Health, latency, failure, and reprocessing visibility per pipeline.
From SCADA tag to ERP record — one pipeline, no scripts.
A reference architecture for shipping OT/IT pipelines on Flex83 without custom glue code.
Pick sources from the connector library — SCADA, MES, ERP.
Drag join, filter, and quality nodes onto the pipeline canvas.
Apply schema and quality rules; preview output on sample data.
Pick cron, event trigger, or dependency-based scheduling.
Flex83 runs the pipeline on managed Flink and Spark runtimes.
Your data team stops being a Spark ops team.
Three things that change when DataOps becomes platform capability.
Ship pipelines in hours, not sprints
OT engineers and data engineers configure visually. New pipelines go live the same day — not after a code review and a release.
Stop being on call for plumbing
Pipelines run on managed runtime. The platform handles recovery, scaling, and reprocessing — not your engineer’s pager.
Pipelines that survive schema changes
Schema registry catches breaking changes before they break the pipeline. Updates ripple through the visual DAG, not through a thousand lines of Python.
OEMs are already shipping multi-tenant SaaS on Flex83.
Source connectors built in — no custom integration
Of glue code for standard OT/IT pipelines
Flink and Spark runtimes — no cluster ops
Per-pipeline health, latency, and failure tracking
Stop writing glue code. Start configuring pipelines.
Talk to a Flex83 platform expert about your DataOps roadmap. We’ll walk you through the pipeline composer, the managed runtime, and what shipping a production OT/IT flow looks like in one afternoon.